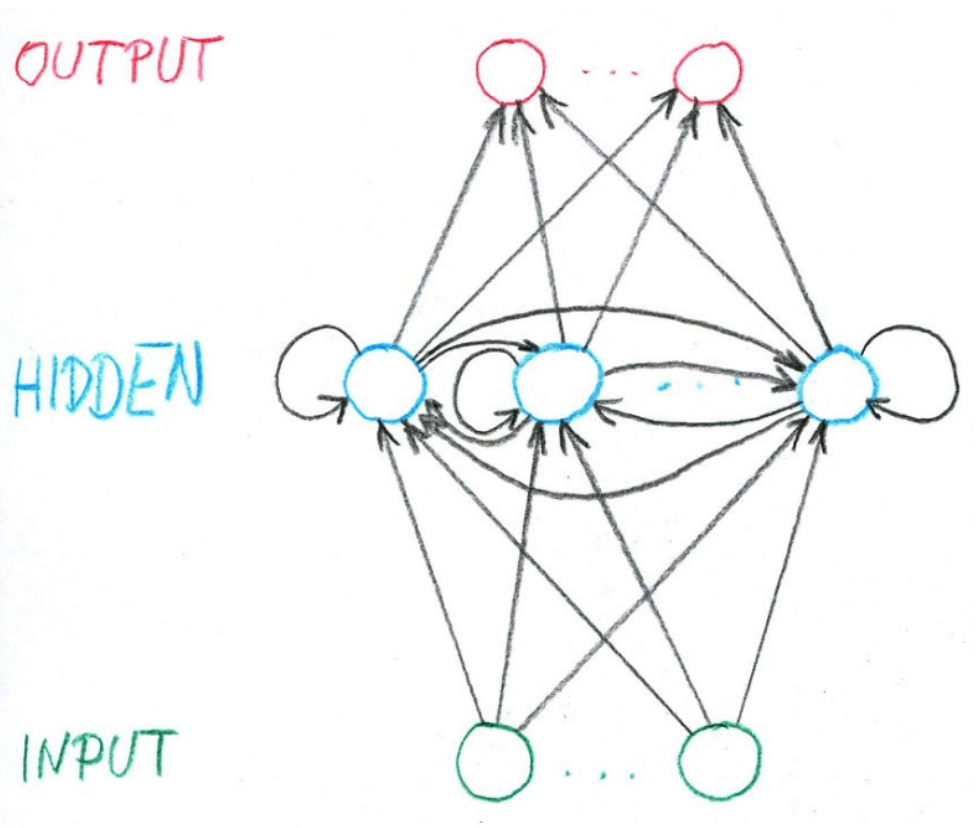
Trénovací set je množina dvojic — (vstupní sekvence, výstupní sekvence).
T={(x1,d1),...,(xp,dp)}
|
Note
|
Ano, to znamená, že xlt1 je první prvek t-ho prvku v l-té vstupní sekvenci.
|
Squared error samplu (x,d):
E(x,d)=t=1∑Tk=1∑N21(ytk−dtk)2
Gradient descent je podobný. Na začátku jsou všechny váhy inicalizovány poblíž 0 a pak iterativně přepočítávány:
Ukk′(l+1)Vkk′(l+1)Wkk′(l+1)∂Ukk′∂E(x,d)∂Vkk′∂E(x,d)∂Wkk′∂E(x,d)=Ukk′(l)−ε(l)⋅∂Ukk′∂E(x,d)=Vkk′(l)−ε(l)⋅∂Vkk′∂E(x,d)=Wkk′(l)−ε(l)⋅∂Wkk′∂E(x,d)=t=1∑T∂htk∂E(x,d)⋅σ′⋅xtk′=t=1∑T∂ytk∂E(x,d)⋅σ′⋅htk′=t=1∑T∂htk∂E(x,d)⋅σ′⋅h(t−1)k′
Za předpokladu squared error je backpropagation:
∂ytk∂E(x,d)∂htk∂E(x,d)=ytk−dtk=k′=1∑N∂ytk′∂E(x,d)⋅σ′⋅Vk′k+k′=1∑H∂h(t+1)k′∂E(x,d)⋅σ′⋅Wk′k
|
Tip
|
Pokud σ′⋅Wk′k≈1, pak gradient buď vybouchne nebo se ztratí.
|
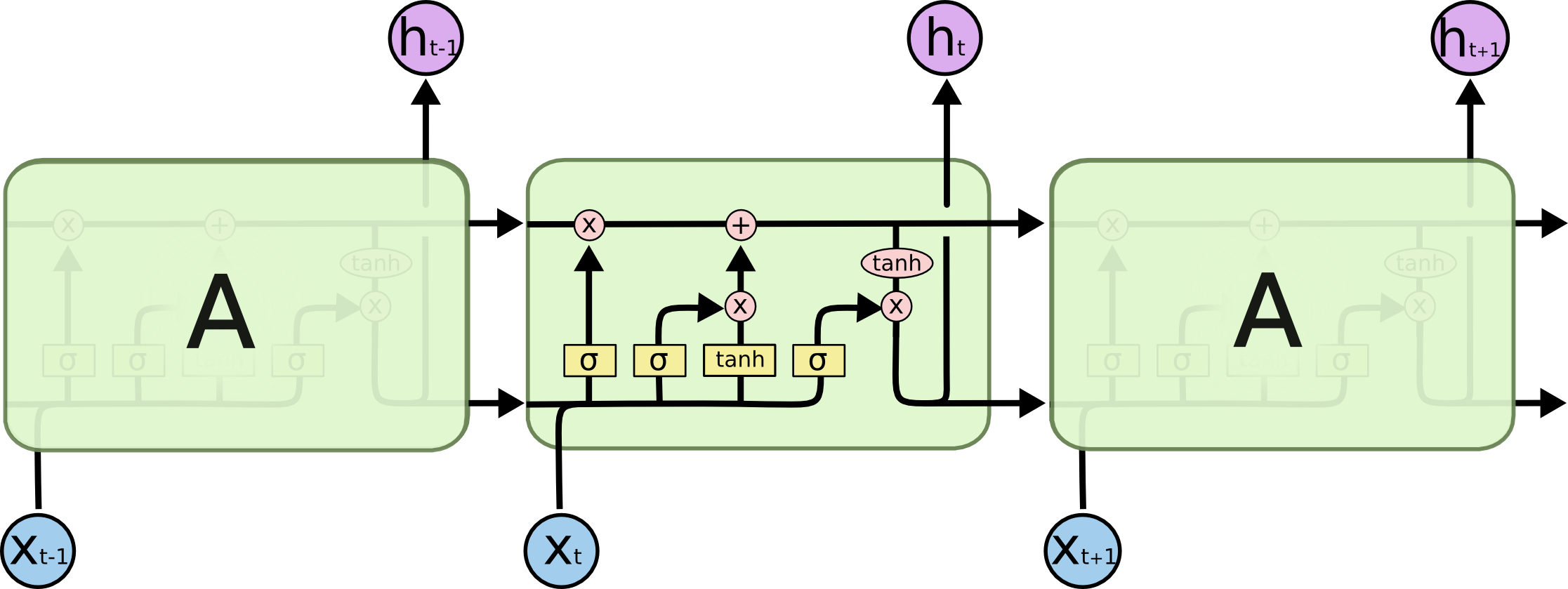
- Long Short-Term Memory (LSTM)
-
LSTM řeší problém s vanishing a exploding gradientem, kterým RNN. V RNN je σ typicky tanh. V LSTM obsahuje jeden hidden neuron vlastně čtyři "podvrstvy", které mimo jiné umožňují část paměti zapomenout: