Trénink
Likelihood
Ve statistice jsou dva pojmy:
- Probability ,
-
Říká, jaká je pravděpodobnost, že daný jev se v našem modelu stane.
- Likelihood
-
Říká, jak dobře náš model (rozdělení pravděpodobnosti náhodné veličiny) sedí na naměřená data.
|
Note
|
Pravděpodobnost je funkce jevů. Likelihood je funkce parametrů modelu. |
|
Note
|
Likelihood nemusí nutně vracet čísla z intervalu . |
Jak to souvisí s trénováním neuronek? Neuronka je model, kde váhy neuronů jsou parametry. Při učení neuronek je naším cílem maximalizovat likelihood, jakožto míru toho, že naše síť sedí na "naměřená data", training set . Tomuhle přístupu se říká maximum likelihood principle.
- Training set
-
je množina samplů, kde jsou vstupní vektory a jejich očekáváné výstupy.
Linear regression
Linear regression je metoda, kdy na základě naměřených dat hledáme linární model. Tedy výstup závisí na vstupech (Ano, může být víc než jeden.) lineárně. Uvažme neuron, kde:
-
vnitřní potenciál ,
-
aktivační funkce je pass-through,
-
výstup je jedno číslo ,
-
množina je trénovací set.
Předpokládáme, že každý očekávaný výstup byl generován takto:
kde je vstup, je normálně distribuovaný šum se střední hodnotou 0, a , a jsou parametry modelu.
|
Note
|
Směrodatná odchylka není aktivační funkce . |
Dále předpokládáme, že šumy byly vygenerovány vzájemně nezávisle.
Naším cílem je najít hodnoty pro červené parametry takové, že maximalizují likelihood:
Kde je hustota pravděpodobnosti, podle které byly očekávané hodnoty vygenerovány za předpokladu fixních .
Všimni si, že je tu podobné normální rozdělení jako u , ale střední hodnotu takovou, aby generovalo , pokud náš model funguje.
|
Note
|
Bez předpokladu normálnosti a vzájemné nezávislosti šumů by to nešlo. |
- Věta
-
Parametry maximalizují likelihood pro libovolné , právě když minimalizují squared error .
|
Note
|
Maximalizace/minimalizace je na odchylce šumu je nezávislá. je maximální, když . |
- Důkaz
-
Jelikož maximalizováním logistic likelihood , maximalizujeme i , pak je maximální (nezávisle na volbě ), pokud je minimální.
Logistic regression
Logistic regression je metoda, kdy na základě naměřených dat hledáme model, kde vztah mezi vstupy a výstupy odpovídá funkci logistic sigmoid. Výsledkem je klasifikace (pravděpodobnost) mezi dvěma třídami 0 a 1. Uvažme neuron, kde:
-
vnitřní potenciál ,
-
aktivační funkce je logistic sigmoid,
-
výstup je jedno číslo z intervalu ,
-
množina je trénovací set.
|
Note
|
Odds (poměr pravděpodobností) je poměr pravděpodobnosti toho, že jev nastane, k pravděpodobnosti toho, že jev nenastane. Tedy pokud má jev pravděpodobnost , pak odds jsou . (Čitatel a jmenovatel dají tedy v součtu 1.) Logaritmus odds nazýváme logit. |
Logistic sigmoid
Proč použít právě logistic sigmoid? Dejme tomu, že opravdová šance, že klasifikovaný objekt patří do třídy 1, je , pak:
což připomíná exponenciální funkci:
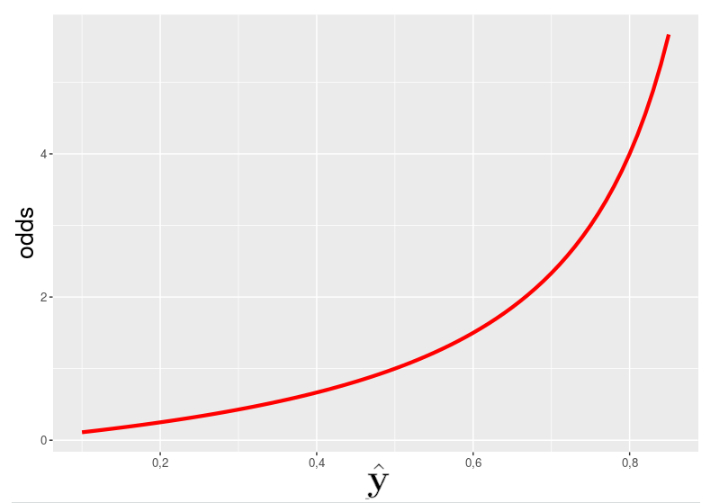
Když ale na obě strany aplikujeme logaritmus:
připomíná spíše lineární funkci:
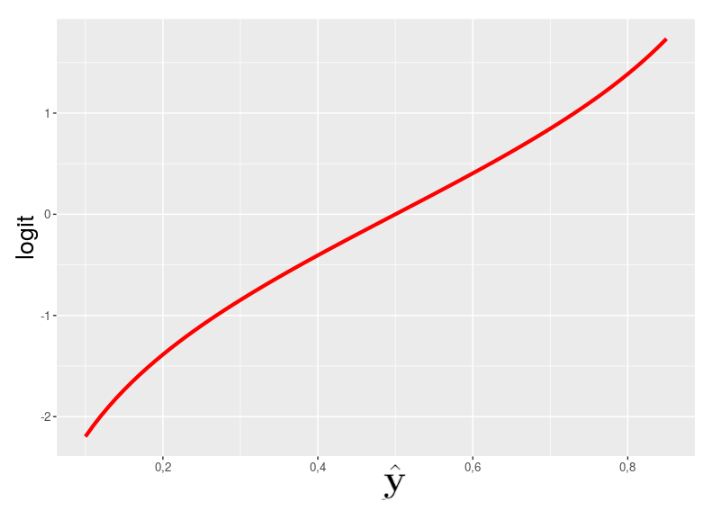
Ale… vnitřní potenciál je taky lineární, ne?
Takže klasifikaci vstupu jako 0 nebo 1 () aproximujeme pomocí funkce logistic sigmoid, pravděpodobností .
Minimalizace likelihoodu
Likelihood v případě binární klasifikace si můžeš představit na hodech mincí (se stranami 0 a 1). Nechť je je odhad pravděpodobnosti tvého logistic sigmoid modelu, že spadne 1, a tvůj dataset. Pak likelihood, že tvůj model vygeneruje právě tenhle data set je:
Když upustíme od příkladu s mincí, pak pro obecnou binarní klasifikaci s datasetem :
Násobení se nám nelíbí, takže stejně jako u linear regression budeme maximalizovat logistic likelihood:
Podobně jako u linear regression chceme spíš minimalizovat nějakou error function . V případě logistic regression volíme binary cross-entropy:
Gradient descent
Gradient descent je algoritmus, který nám umožňuje najít váhy takové, že hodnota error function bude minimální. Jdeme proti směru gradientu (vektoru parciálních derivací ). Gradient udává směr, kterým funkce roste nejrychleji:
Gradient descent funguje iterativně, přižemž v 0-té iteraci jsou váhy inicializovány náhodnými čísly blízko 0. Pro následující iterace pak platí:
ADALINE
ADALINE je jeden neuron ze 60. let, co dělá lineární regresi. Pokud za zvolíme squared error :
|
Note
|
Věta (Widrow & Hoff) Pokud , pak posloupnost , , … konverguje ke globálnímu minimum . |
Multilayer Perceptron
U feed-forward sítí jakou je MLP, se pro výpočet gradientu používá backpropagation:
Za předpokladu, že je squared error, pak:
Představ si, že při derivaci podle , kde není výstup, tě zajímají jen členy , protože jen při vyhodnocení neuronů je hodnota potřeba, takže všechno ostatní se zderivuje na konstantu.
|
Note
|
Uvědom si, že tyhle derivace se počítají po vrstvách v obráceném pořadí než, když NN vyhodnocuješ. To znamená, že hodnotu už spočítanou máš, protože jsi ji počítal v minulé vrstvě. |
-
Inicializuj .
-
forward pass — vyhodnoť NN pro sample (t.j. pro všechny )
-
backward pass — od konce pro každou vrstvu spočítej
-
pokud , pak
-
pokud , a je v -té vrstvě, pak
-
-
weight update — pro všechna spočítej
-
-
obsahuje výslednou hodnotu
|
Note
|
Tenhle algoritmus předpokládá za error function squared error a za funkci, která fakt bere za parametr jen vnitřní potenciál jednoho neuronu a ne třeba celé vrstvy, jak to dělá softmax. |
|
Note
|
Co se časové složitosti týče, tak je tenhle algoritmus lineární vzhledem k počtu vrstev NN. Nicméně tohle je jen jedna iterace, časovou složitost minimalizace gradientu nejde odhadnout. |
- Online Gradient Descent
-
Samply bereš po jednom , takže:
- Stochastic Gradient Descent (SGD)
-
Sample nebereš po jednom ale po malých randomizovaných várkách — minibatchích :
- Learning rate
-
Hyperparametr ovlivňující rychlost učení. Může záviset na iteraci , pak je to funkce .
- Epocha
-
Jeden průchod celým trénovacím setem.
Error functions
Přehled error functions v tomto kurzu:
- Squared error
-
- Mean squared error
-
- Binary cross-entropy
-
- (Categorical) cross-entropy
-
Používá se při multi-class classification (např. číslice v MNISTu). Klasifikační sítě zároveň prakticky vždy mají výstupní vrstvu s aktivační funkcí softmax, neboť pak pro váhy mezi předposlední a poslední, softmax vrstvou platí:
NotePro vysvětlení, jak a proč tohle funguje, čti tohle.