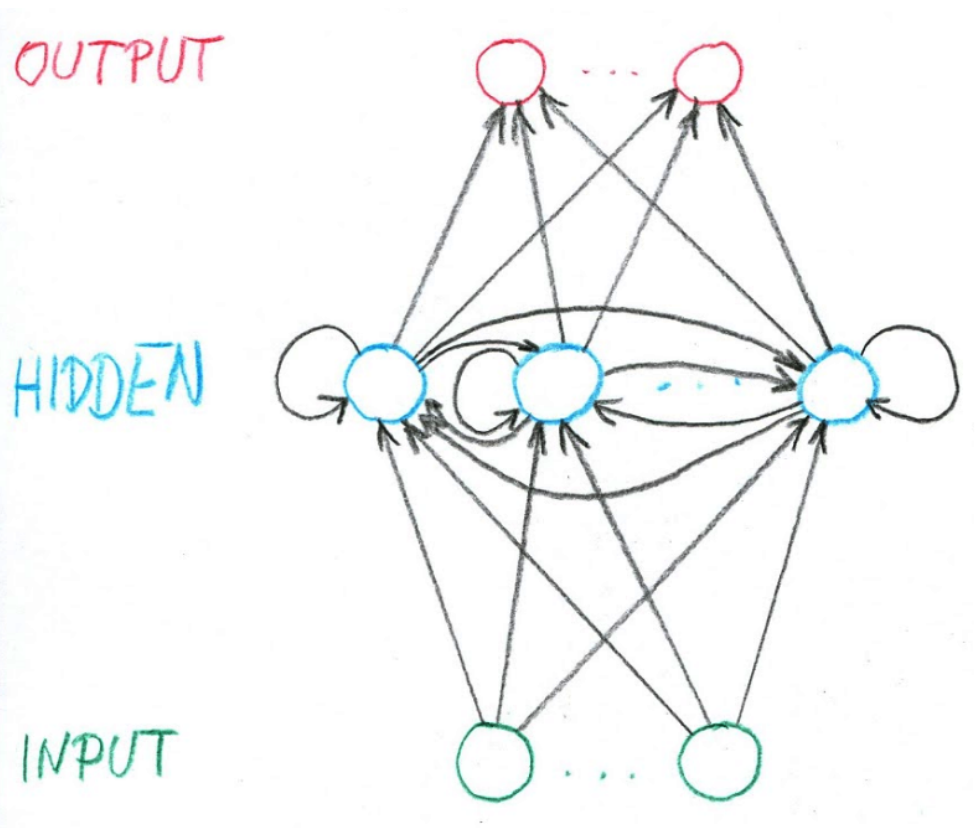
Recurrent Neural Network (RNN)
Architektura, která (na rozdíl od MLP) povoluje cykly. Je to MLP rozšířená minimálně tak, aby byla rekurentní. RNN dovedou zpracovat vstup variabilní délky. Mají "paměť". Jejich hlavní doménou je zpracování textu.
Notace
-
— vektor hodnot input neuronů
-
— vektor hodnot hidden neuronů
-
— vektor hodnot output neuronů
-
— váha z inputu do hidden (dst ← src)
-
— váha z hidden do hidden (dst ← src)
-
— váha z hidden do output (dst ← src)
|
Note
|
Zdá se, že všechno v tomhle předmětu používá Intel syntax dst-src. |
Aktivita
Výstup z hidden neuronů je pamětí neuronky, která je na začátku inicializována na 0. RNN zpracovává sekvenci vstupů délky . Váhy neuronů jsou sdíleny napříč sekvencí — na každý prvek jsou aplikována ta samá :
A produkuje sekvenci hiddenů a outputů:
Často se pro přehlednost používá maticová notace, kde pro input a hidden posloupnosti platí:
Pro output sekvenci pak:
Trénink
Trénovací set je množina dvojic — (vstupní sekvence, výstupní sekvence).
|
Note
|
Ano, to znamená, že je první prvek -ho prvku v -té vstupní sekvenci. |
Squared error samplu :
Gradient descent je podobný. Na začátku jsou všechny váhy inicalizovány poblíž 0 a pak iterativně přepočítávány:
Backpropagation
Za předpokladu squared error:
Long Short-Term Memory (LSTM)
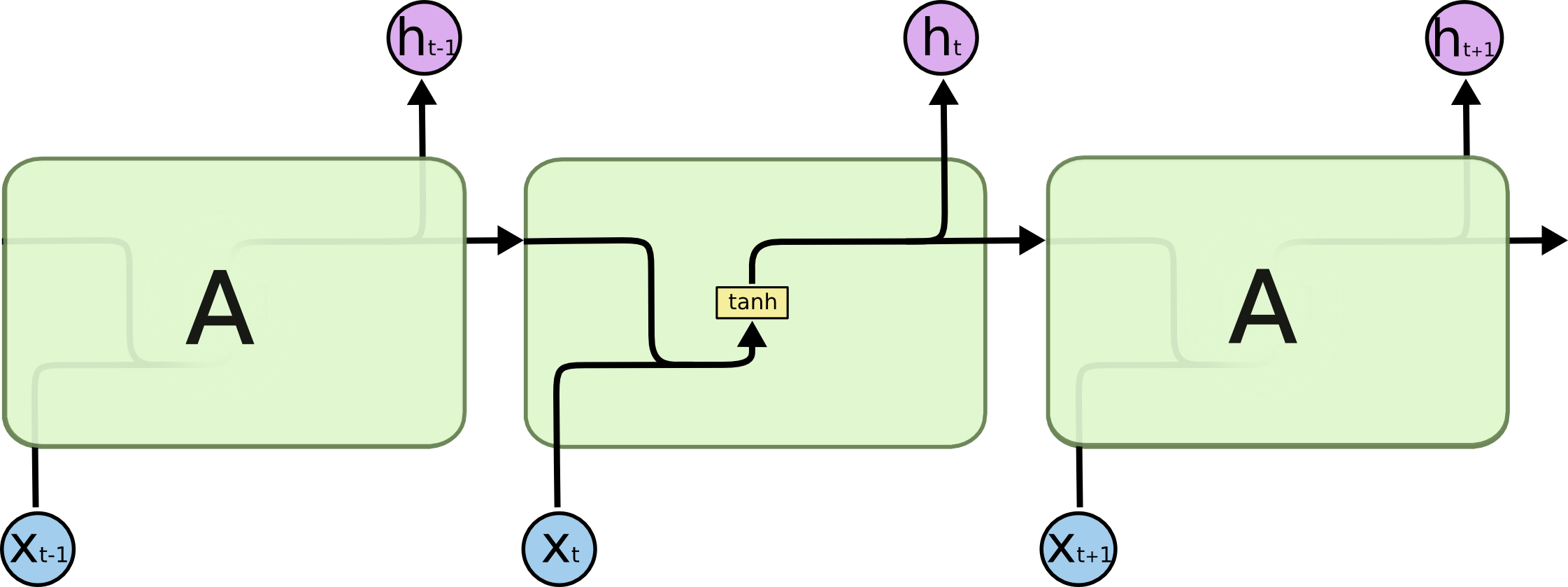
RNN popsané výše mají dost problém s vanishing (nebo exploding) gradientem, pokud se nepohybuje blízko 1. Napamatují si dost kontextu. LSTM tento problém řeší.
Buňka v klasické RNN bere aktuální prvek sekvence a hidden výstup z minulé iterace a prohání ho skrz jednu tanh vrstvu:
LSTM je maličko komplikovanější, protože každá "buňka" vlastně obsahuje 4 vrstvy:
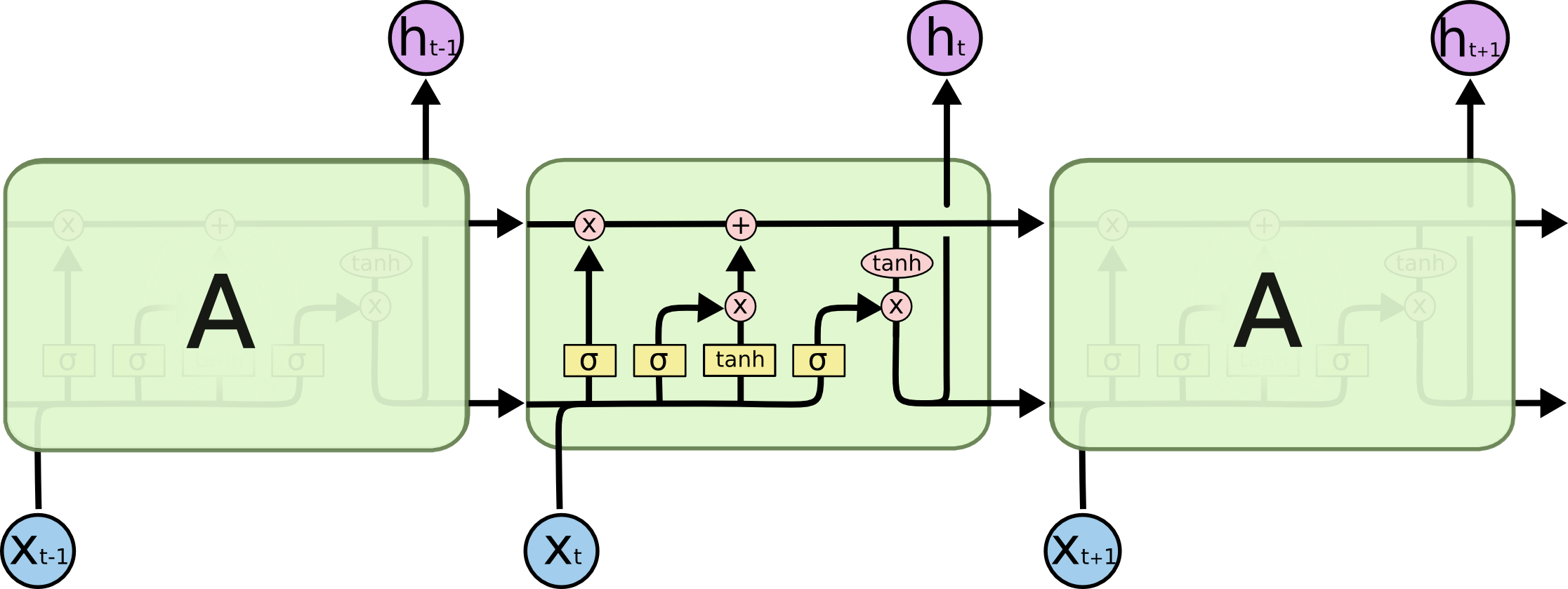
Podívejme se blíže:
- Logistic sigmoid
-
Aktivační funkce logistic sigmoid — vždy vrací číslo mezi nulou a jedničkou — ideální pro pravděpodobnosti.
- Čára
-
Stav buňky, do kterého se "vlévají" úpravy.
- Operace
-
Matrix product.
- Operace
-
Component-wise product.
- Forget gate
-
Umožňuje si něco z minulého stavu ponechat nebo zapomenout.
- Input gate
-
Rozhoduje, co za informace vůbec chceme modifikovat.
- Kandidátní stav
-
tanh vrstva z původního RNN vytváří kandidátní stav.
- Stav
-
Nový stav vznikne aplikací input gate a forget gate na kandidátní stav.
- Output gate
-
Rozhoduje, co ze stavu si záslouží dostat se ven z buňky.
- Output
-
Použití output gate obohacené o tanh, který hodnoty stavu vměstná do intervalu .
|
Note
|
Obrázky ukradeny z výborného článku Understanding LSTM Networks, který napsal Christopher Olah. |