Multilayer Perceptron (MLP)
Notace
MLP je feed-forward architektura NN, kde jsou neurony rozděleny do vrstev — jedné vstupní, jedné výstupní a libovolného počtu skrytých vrstev uprostřed. Input layer má index 0. Každý neuron v i-té vrstvě je napojen na každý neuron v (i + 1)-ní vrstvě.
-
— množina input neuronů
-
— množina output neuronů
-
— množina všech neuronů
-
Neurony mají indexy , , …
-
— vnitřní potenciál neuronu po skončení výpočtu
-
— výstup neuronu po skončení výpočtu
-
— hodnota formálního jednotkového vstupu (kvůli biasům)
-
— váha spojení z neuronu do neuronu (dst ← src)
-
— bias — váha z formální jednotky do neuronu
-
— množina neuronů , jenž mají spojení do (j ← i)
-
— množina neuronů , do nichž vede spojení z (j → i)
Aktivita
- Pravidlo pro výběr neuronů při výpočtu
-
V i-tému kroku vezmi i-tou vrstvu.
- Vnitřní potenciál neuronu
-
- Aktivační funkce neuronu
-
(třeba logistic sigmoid)
- Stav nevstupního neuronu
-
resp.
Aktivační funkce
- Unit step function
- Logistic sigmoid
-
Kde je steepness parametr.
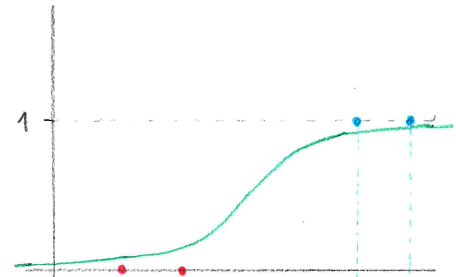
- Hyperbolic tangens (tanh)
-
- Rectified Linear Unit (ReLU)
Důkazy
Boolovské funkce
- Věta
-
Dvouvrstvý MLP, kde každý neuron má za unit step function, je schopný spočítat libovolnou boolovskou funkci .
- Důkaz
-
Pro každý vstup takový, že , zkonstruujeme neuron jehož výstup bude 1, právě když jeho vstup je :
-
-
Všechny neurony zapojíme do jednoho neuronu, jenž počítá OR.
-
Podmnožiny vstupního prostoru (3 vrstvy)
- Věta
-
Třívrstvý MLP, kde každý neuron má za unit step function, dovede aproximovat libovolnou "rozumnou" podmnožinu vstupního prostoru.
- Důkaz
-
Daná podmnožina se dá obalit hyperkostkami (t.j. čtverci 2D, kostkami ve 3D, …) — na to stačí dvě vrstvy (první udává nadroviny, druhá volí, která "strana" nadroviny ohraničuje hyperkostku). Třetí vrstva je pak OR, který spojuje hyperkostky nadefinované v prvních dvou vrstvách.
Podmnožiny vstupního prostoru (2 vrstvy)
- Věta (Cybenko 1989)
-
Dvouvrstvý MLP, kde každý hidden neuron má za nějakou sigmoidal funcion, tedy platí:
a pokud každý output neuron má lineární , pak tato síť dovede aproximovat libovolnou "rozumnou" množinu — tedy pro "většinu" vektorů platí, že , právě když výstup sítě pro vstup .
Libovolná spojitá funkce (3 vrstvy)
- Věta
-
Třívrstvý MLP, kde každý output neuron má lineární (pass-through) a ostatní mají za logistic sigmoid, dovede "spočítat" libovolnou funkci . "Spočítat" zde znamená, že pro každé platí , kde je výstup sítě a je povolená chyba.
- Důkaz
-
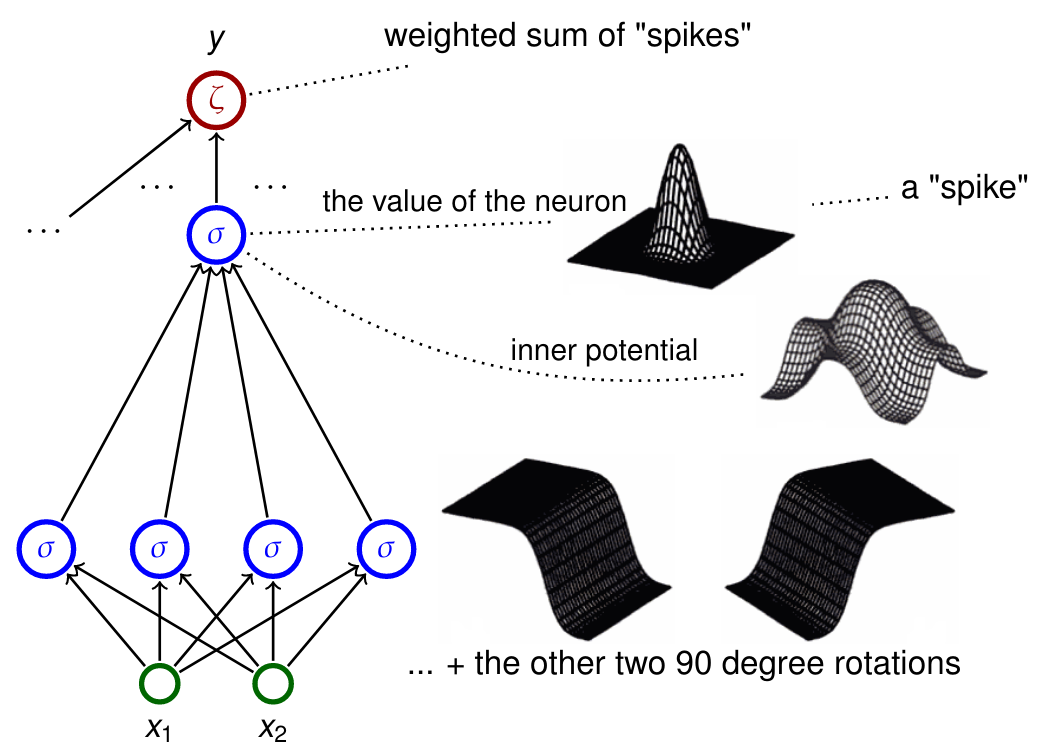
Libovolná spojitá funkce (2 vrstvy)
- Věta (Cybenko 1989)
-
To samé co věta výše, ale zvládl to jen se dvěma vrstvami.
Výpočetní síla
Uvažme neuronové sítě, které:
-
jsou rekurentní (mají cykly),
-
mají reálné váhy,
-
mají jeden input a jeden output neuron,
-
mají paralelní pravidlo pro výběr neuronů při výpočtu — všechny neurony se vyhodnotí v každém kroku,
-
mají aktivační funkci
Slova kódujeme jako reálná čísla následujícím způsobem:
|
Warning
|
Takže např. z bude . Všimni si té zaražející jedničky na konci. Jak jinak bys poznal, že to slovo skončilo. |
Síť rozpoznává jazyk , pokud počítá funkci , kde , takovou, že:
|
Note
|
Rekurentní neuronové sítě s racionálními vahamy jsou ekvivalentní Turingovým strojům.
|
|
Note
|
Rekurentní neuronové sítě s reálnými vahami jsou silnější než Turingovy stroje.
|
Prakticky jsou ale takové sítě extrémně velké. Hodnota NN tak spočívá spíš v jejich schopnosti se učit, možnosti generalizace, robustnosti (chyby v inputu je jen tak nerozhodí) a masivní paralelizaci.