Convolutional Neural Networks (CNN)
Konvoluční sítě jsou neuronky specializující se na obrázky. Mají nové typy vrstev: konvoluční a pooling.
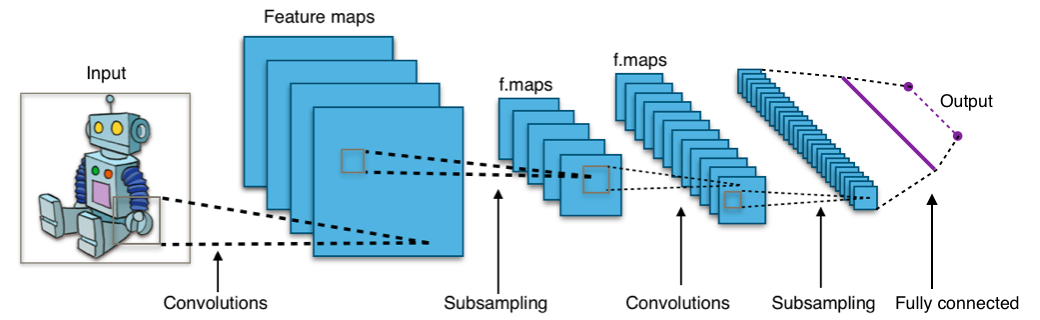
|
Note
|
By Aphex34 - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=45679374 |
Nové vrstvy
- Konvoluční vrstva
-
Každý neuron je napojen jen na malý receptive field neuronů o vrstvu níže, který se posouvá o daný stride. Za to však všechny neurony v konvoluční vrstvě sdílí stejné váhy a biasy, což jim umožňuje naučit se nějaký vzor o velikosti receptive field — říkáme, že taková vrstva je feature mapa. Jelikož takových vzorů se chceme zpravidla naučit více, máme vícero vzájemně nezávislých feature map napojených na stejnou vstupní vrstvu.
Jinak jsou to ale staré dobré neurony s vnitřním potenciálem a aktivační funkcí.
- Pooling vrstva
-
Nemají váhy. Slouží ke snížení počtu parametrů. Každý neuron počítá nějakou jednoduchou funkci na svém receptive field:
-
max-pooling — maximum,
-
L2-pooling — square root of sum of squares,
-
average-pooling — mean.
-
Notace
-
— množina input neuronů
-
— množina output neuronů
-
— množina všech neuronů
-
Neurony mají indexy , , …
-
— vnitřní potenciál neuronu po skončení výpočtu
-
— výstup neuronu po skončení výpočtu
-
— hodnota formálního jednotkového vstupu (kvůli biasům)
-
— váha spojení z neuronu do neuronu (dst ← src)
-
— bias — váha z formální jednotky do neuronu
-
— množina neuronů , jenž mají spojení do (j ← i)
-
— množina neuronů , do nichž vede spojení z (j → i)
-
— množina spojení (dvojic neuronů) sdílících váhu
Trénink
Stochastic gradient descent můžeme mírně upravit a použit i na konvoluční sítě.Zvolme náhodně minibatch z trénovacího setu . Za error function si volíme mean squared error:
SGD počítá posloupnost vah .
-
Inicializujeme náhodně na hodnoty v okolí 0.
-
V kroku vypočítáme:
Backpropagation
Pro dense vrstvy platí to samé, co u MLP:
U konvolučních vrstev nestačí pro každou váhu spočítat , protože pro každou váhu existuje víc než jeden výstup . Tedy:
Předpokládejme dále, že error function je squared error. Pokud , platí:
Pokud a je dense nebo konvoluční vrstva, platí:
Pokud a je max-pooling, pak a platí:
|
Note
|
Max-pooling nemá váhy, takže vzorec výše se zabývá vrstvou před max-poolingem, kde pouze neurony, jejichž index () je index toho maximálního si zkopírují parciální derivaci z max-pooling vrstvy. |