-
Spatial — e.g., large areas of homogenous color
-
Temporal — e.g., many pixels unchanged between consecutive frames
Compression
- Compression
-
-
Encoding data to take up less storage space / bandwidth at the cost of additional decoding calculations.
-
Algorithmical perspective: The goal is to remove redundancy.
-
- Coding redundancy
-
When we use more code symbols (bits) than is necessary.
- Psychovisual and psychoacoustic redundancy
-
Most things we humans see and hear contain low frequencies. If we remove the high-frequency data, the difference is near imperceivable.
- Spatial and temporal redundancy
-
When the value of a sample can be reasonably predicted from the values of neighboring samples.
- General compression model
-

-
— original input signal
-
— input signal after compression and decompression
-
if , then the compression is lossless
-
if , then the compression is lossy
-
encoder — filter responsible for signal compression
-
decoder — filter responsible for signal decompression
-
- LZW coding (Lempel-Ziv-Welch)
-
-
GIF, TIFF, PDF, ZIP
-
Designed for the compression of text.
-
Doesn’t need to transmit a dictionary or a probability table, only the base set.
-
When the dictionary is full, we discard it and start a new one.
-
- Entropy coding
-
-
Lossless compression method that remaps elements of data based on their statistical properties.
-
Assigns shorter codes to frequently encountered data.
-
- Arithmetic coding
-
-
Form of entropy coding. Maps the entire message onto a single arbitrary-precision fractional number in range 0 to 1 (i.e., arithmetic code word).
-
The input signal is usually very long. Therefore, it is split into sequences of fixed size.
-
If the length of sequences increases, the interval for the generated word is smaller and number of required bits increases.
-
- Huffman coding
-
Form of entropy coding. A prefix code assigning shorter codes to frequent values.
Algorithm:
-
Order the source symbols based on their probability of appearance.
-
Reduce/merge the two lowest probable symbols into a new single symbol.
-
Repeat tyhe reductions until it is no longer possible.
-
Get the coding tree.
-
Mark the tree nodes with binary code (left → 0, right → 1).
-
Use the path to each source symbol (leaves) to encode their new code.
-
- Context-Adaptive Binary Arithmetic Coding (CABAC)
-
-
Form of entopy coding used in AVC and HEVC.
-
Uses multiple probability models and switches between them based on context.
-
- Lossless predictive encoding
-
-
Input — the original signal to be encoded.
-
Predictor — function that estimates the next piece of data based on predecessors (e.g., weighted average).
-
Example:
-
-
Error
-
Can be used as a preprocess stage before Huffman or some other symbol encoder.
-
Best when we know what "trends" in the data we can expect.
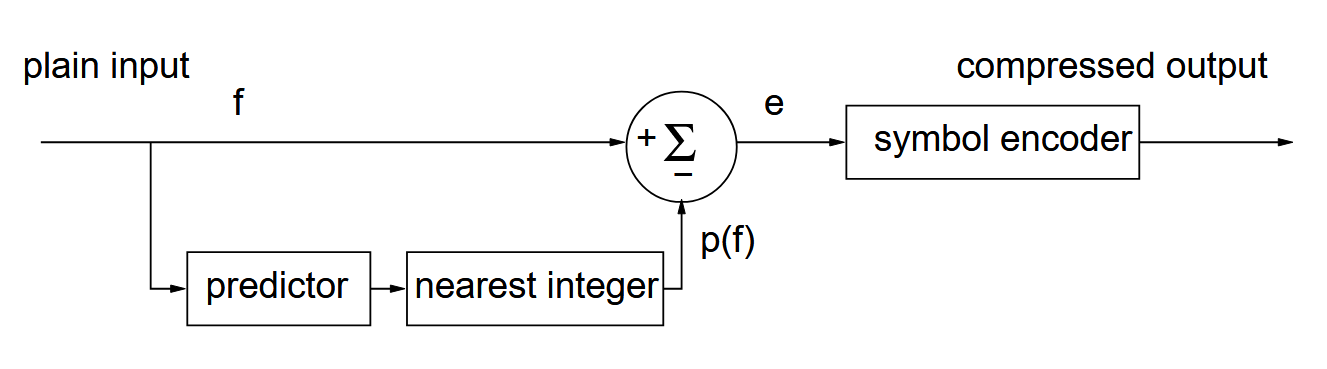
The decoder must know what the predictor is!
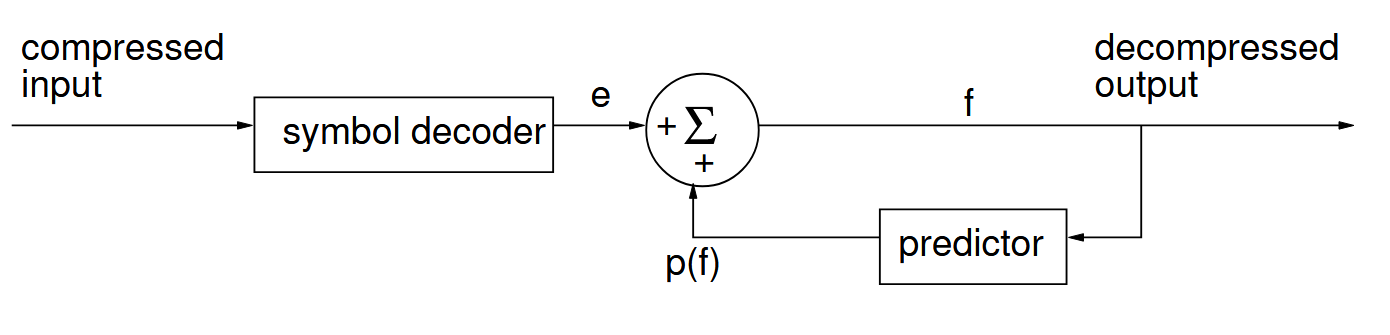
-
- Lossy predictive coding
-
-
Has much higher compression ratio than lossless.
-
Decoded data is not the same as the original (before encoding) data.
-
Quantizer — reduces the amount of bits required to express the value but loses information (i.e., division).
-
The first value of input is passed as is (i.e., its predicted value is 0). It is then quantized, and then fed to the predictor to get the predicted value for the next value of f.
-
The predictor is used on its own output (i.e., in a feedback loop) so that it can be used the same way in the encoder as well as the decoder. If it were used only on the original input values, decoder would quickly accumulate undesired error.
-
Example: Delta modulation (DM) — error is always either a positive or negative
-
, where is a prediction coefficient ()
-
, where is a positive constant.
-
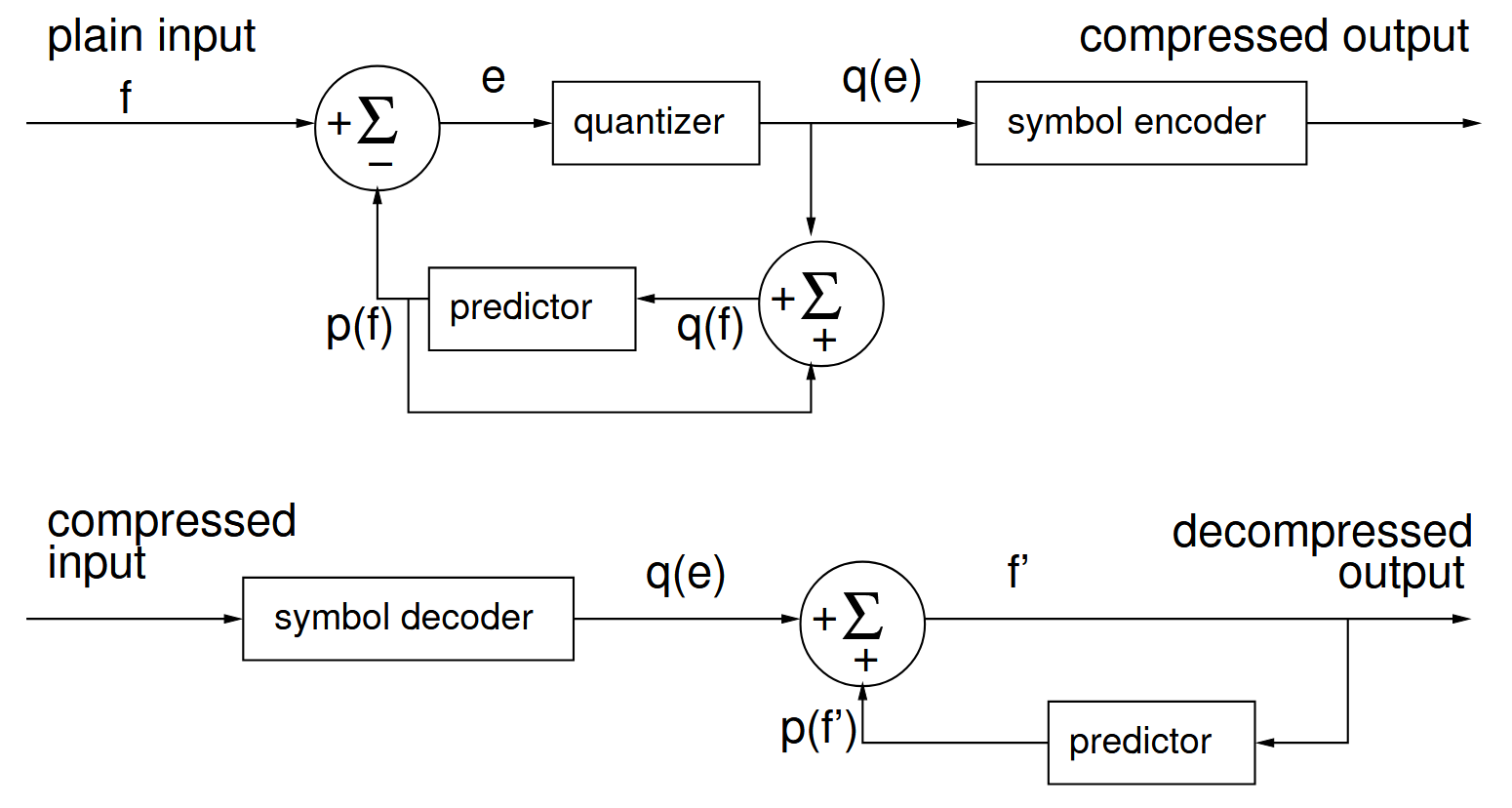
-
- Transform coding
-
-
Compression happens in the frequency domain instead of the original data.
-
We typically use DFT or DCT and disregard high frequencies.
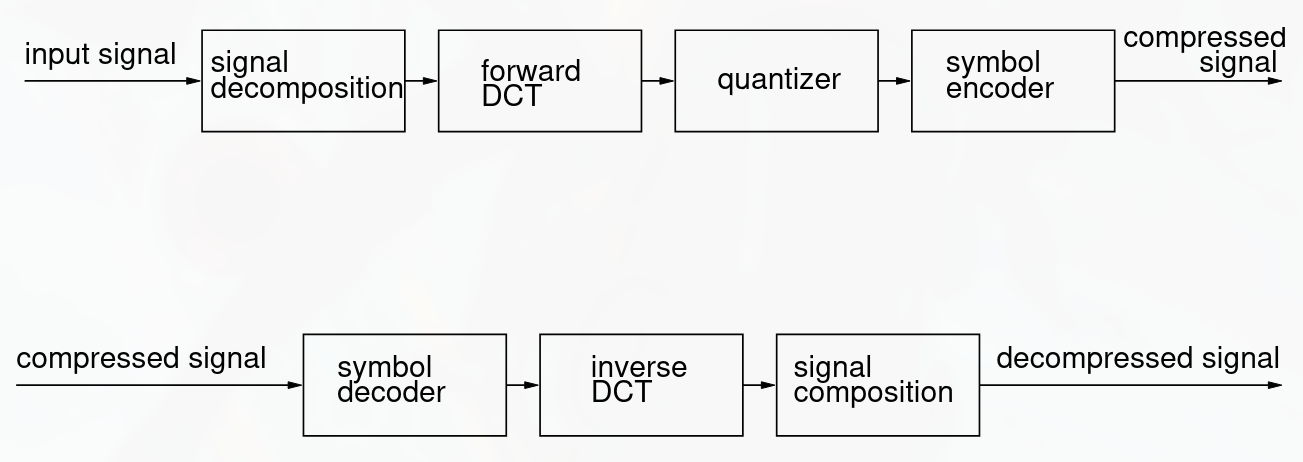
-
- Run length encoding (RLE)
-
-
Lossless.
-
Stores repeated runs of data as a single occurrence along with the number of occurrences.
-
green green green green green⇒ (green, 5) -
Most useful on data where these runs are common (e.g., palleted icons, pixel art, etc.)
-
Image Compression
- CCITT Group 3
-
-
Consultative Committee for International Telephony and Telegraphy
-
Used for transmission fax machines for black-and-white bitmaps.
-
A combination of Huffman and RLE.
-
Also called Modified Huffman coding.
-
Code words for lengths 1-2560 are stored in well-known table. One table for black pixels, another for white pixels.
-
Run lengths represented by zero or more make-up code words and one terminating code word.
-
0-63 pixels runs are encoding using just the one terminating code work.
-
Example: 2561 black pixels (= 2560 + 1) →
0000_0001_1111|010
-
-
Each line ends with EOL
0000_0000_0001.
-
- CCITT Group 3 2D
-
-
Images divided into groups of lines each (typically is 2 or 4).
-
First line of each group is encoded by CCITT Group 3.
-
The rest is encoded using a differential scheme with new code words specific for 2D encoding.
-
- CCITT Group 4
-
-
Like CCITT Group 3 2D but .
-
Used for storage on disk drives.
-
No EOL codes.
-
Used in TIFF compression Type 4
-
- Chroma subsampling
-
-
Using less bandwidth for chroma than for luma.
-
Humans are more likely to notice difference in black-white, than in color.
-
- YUV
-
-
Y = luma, U, V = chroma
-
- YCbCr
-
-
Y = luma, Cb = blue-difference chroma (B-Y), Cr = red-difference chroma (R-Y)
-
YUV expressed differently
-
- Subsampling scheme
-
-
Describes the number of samples for each channel in a 2-pixel-high conceptual region.
-
where
-
= width of the conceptual region (thus the number of luma samples)
-
= number of chroma samples (Cb, Cr) in the first row of pixels
-
= number of chroma changes (Cb, Cr) between the two rows of pixels (typically 0 or same as )
-
-
- JPEG
-
-
Joint Photographic Experts Group
-
The image format is actually JPEG File Interchange Format (JFIF)
-
Relies on Discrete Cosine Transform (DCT).
Algorithm:
-
Convert RGB to YCbCr.
-
Reduce resolution of Cb and Cr by 2 (i.e., subsampling scheme 4:2:0).
-
Process each of Y, Cb, Cr independently.
-
Split into 8x8 blocks.
-
Apply 8x8 forward DCT on each block.
-
Quantize each block by dividing it with a constant quantization matrix.
-
One matrix for Y, different for Cb and Cr. Both empirically derived and emphasizing lower frequencies, resulting in many zeroes in lower right corner.
-
The quantization matrix is multiplied by the -scale (1-100 %) quality factor.
-
-
Use lossless predictive coding on the quantized DC coefficient of each block.
-
Effectivelly store the average color of each block.
-
-
Store quantized AC coefficients in a zigzag pattern and use RLE.
-
Since most of the zeroes are in the lower right corner, the zigzag patterns creates long runs of zeroes.
-
-
Use Huffman/arithmetic coding on zero run-lengths and magnitude of AC values.
-
- JPEG 2000 (J2K)
-
-
Hierarchical
-
Relies on Discrete Wavelet Transform (DWT).
-
Has a lossy and lossless mode.
-
Image is partitioned into tiles > precincts > code-blocks.
-
Eliminates blockiness typical for JPEG (because it uses DWT and processes the image as a whole or in very large blocks).
-
Simple modification (e.g., rotation or crop) or reading of special regions of interest (ROIs) do not require decompression.
Algorithm:
-
Cut into tiles of size greater than 128x128 to prevent blocking artifacts but enabling ROI selection.
-
DC level shift for channel of bit depth so that they are centered around 0.
-
For example, shifts 8-bit images from range [0, 255] to [-128, 127].
-
This makes some of the later calculations easier.
-
-
Convert from RGB to YCbCr. Either in a lossy or lossless way.
-
Apply DWT with lifting to each tile independently.
-
Level of detail of DWT is a compression parameter.
-
-
Quantize the DWT coefficients for each subband individually (or leave as is in lossless mode).
-
Divide each DWRT subband intop rectangular blocks, precincts.
-
Divide each precint into non-overlapping rectangles, code-blocks.
-
Encode each code-block using arithmetic encoding.
-
Coefficients in a code-block are separated into bitplanes and read in order from most-significant bit to least-significant bit
-

-
- PNG
-
Uses DEFLATE, a combination of LZ (Lempel-Ziv) and Huffman coding.
Video Compression
- Hybrid Block Based Video Coding
-
-
Each video frame is split into (square) blocks.
-
Called superblocks, macroblocks, coding units depending on the codec.
-
Size depends on the codec.
-
Can be processed line-by-line, or sliced/tiled and processed in parallel.
-
Hybrid = combines inter & intra prediction with transform coding (e.g., DCT + quantization + entropy coding).
-
Blocks can be split in various ways, much like in a quadtree.
-
- Encoding loop
-
Each block in the block tree is processed:
-
Subtract prediction (intra or inter) from the input block, resulting in an error signal.
-
Transform the signal (e.g., using DCT or DST).
-
Quantize the signal ("round" the coefficients to fewer levels).
-
This is where a lot of the information in an image is lost.
-
Quantized coefficients are put into the bitstream.
-
-
Entropy coding (e.g., arithmetic coding)
-
Includes also motion information, prediction modes, block sizes, etc.
The processed block is reconstructed and used for encoding the next block:
-
-
Inverse quantization
-
Inverse transformation
-
Prediction and all of the motion information and other data is used in loop filtering
-
Deblocking filter — smoothing filter on block borders to make their boundaries less visible.
-
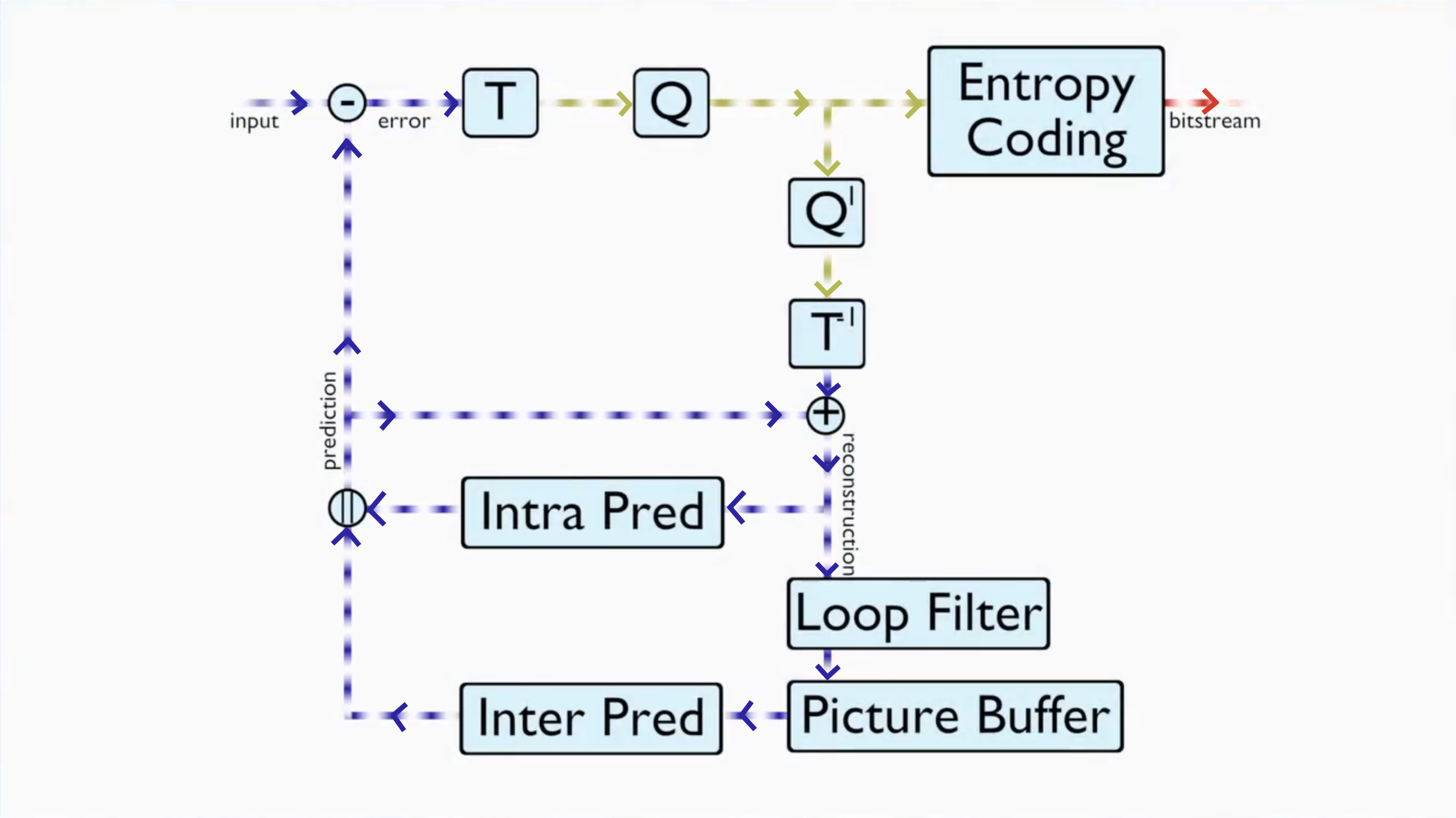
Decoder would do the same except the part in the upper left corner of the image. (It wouldn’t subtract the input because there is no input to be encoded.) The entropy coding is reversed. The picture buffer contains the decoded video.
-
- Intra prediction
-
-
Predicting the contents of a block using surrounding pixels.
-
Has a direction associated.
-
Many different prediction modes (mathematical formulas).
-
Different sets for different codecs.
-
-
- Inter prediction / motion compensation
-
-
Predicting the contents of a block based on the previous reference frame.
-
Typically associated with a direction and an offset.
-
- Frame coding order
-
-
The order in which frames are encoded is not the same as the order in which they are diplayed (chronological).
-
Allows for bidirectional motion compensation — predicting the frame based on the temporally past and temporally future frames.
-
Weighted combination of motion vectors from the two frames.
-
-
- Drift
-
Bad artifacts resulting from encoder and decoder not using the same prediction methods and other implementation details.
- Wavefront decoding
-
Decoding as many block as parallel, provided block to the top and left have been processed. The effect looks like a diagonal "wave".
- MPEG
-
-
Moving Pictures Experts Group
-
Relies on DCT and predictive coding.
-
- Advanced Video Coding (AVC, h.264, MPEG-4 Part 10)
-
-
Published in 2004.
-
Relies on DCT
-
Macroblocks (maximum 16x16)
-
Intra-/independent frames (I-frames)
-
Relatively few (e.g., 1/30 depending on framerate).
-
Frequency varies. One is typically at the start of a scene.
-
Uses a JPEG-like compression.
-
-
Predicted frames (P-frames)
-
Difference to a previous P- or I-frame.
-
-
Bidirectional frames (B-frames)
-
Most common
-
Difference between the current frame and a prediction of it based on the previous I- or P-frame and the next P-frame.
-
-
Seemingly can also use DWT for specific purposes, such as encoding of textures and watermarking.
-
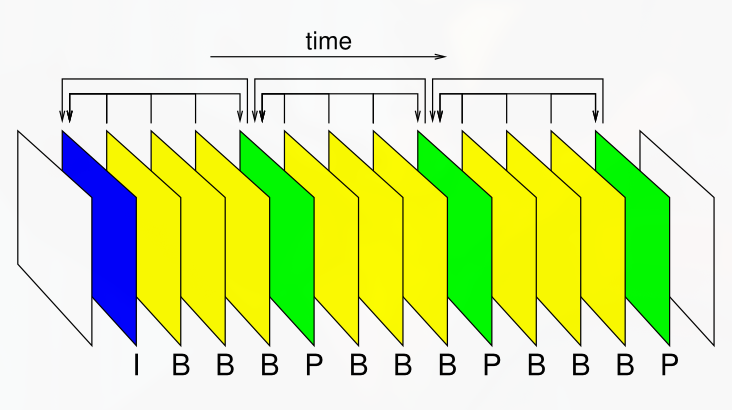
Obrázek 1. Chronological order of frames in a video
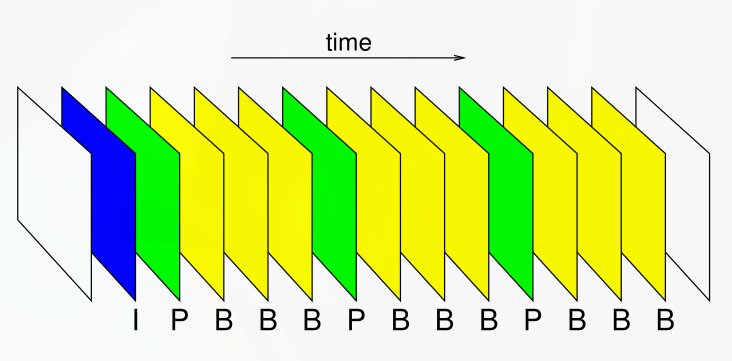
Obrázek 2. Coded order of frames in a video
- High Efficiency Video Coding (HEVC, h.265, MPEG-H Part 2)
-
-
Published in 2013.
-
Successor to AVC
-
More prediction modes than AVC (9 → 35)
-
Macroblocks renamed to Coding Tree Units
-
Costly licensing.
-
Relies on both DCT and DST (discrete sine transform).
-
- VP9
-
-
Published in 2013.
-
Royalty-free.
-
- AOMedia Video 1 (AV1)
-
-
Published in 2018.
-
AOMedia = Alliance for Open Media
-
Industry consortium with Amazon, Apple, Cisco, Google, Intel, Meta, Microsoft, etc.
-
-
Open standard, royalty-free (h.265 is not).
-
Macroblocks of up to 128x128.
-
Questions
- Explain the difference among coding redundancy, spatial/temporal redundancy, and psychoacoustic redundancy.
-
-
Coding redundancy — when more bits are used than needed.
-
Spatial/temporal redundancy — when samples can be predicted based on neighboring samples.
-
Psychoacoustic redundancy — removing high-frequency (sound) information because we don’t hear them.
-
- What does quantizer do?
-
Maps values from a large set onto values from a smaller set, while preserving the most important information (e.g., visible/audible by humans) [quantization].
- How does the arithmetic decoder know when it should stop decoding one codeword?
-
-
The input sequences have a fixed length.
-
There is an End of Message symbol.
-
- How does the encoder deliver the dictionary to the receiver’s decoder in LZW compression scheme?
-
It doesn’t. Only the base symbol set may have to be sent. The dictionary is reconstructed on the fly.
- Explain the meaning of predictor and error in lossless predictive coding scheme.
-
-
Predictor can leverage some known characteristic of the data to predict the next value based on the previous values.
-
If the error — difference between the prediction and the actual input — is small, it can be encoded more efficiently.
-
- Explain the main idea of employing DCT into a transform coding compression scheme.
-
It allows compression through the removal of psychovisual/psychospatial redundancy. Using DCT we transform the signal into the frequency domain, remove near-imperceivable frequencies, and encode the data using the DCT coefficients (usually further compressed using e.g., arithmetic coding).
- Why do we convert RGB into YCrCb in JPEG and JPEG2000 standard?
-
Because in YCrCb we can throw away some information about color. This works because human eyes are kinda crap and see color way worse than luminance.
- Explain the meaning of luminance/chrominance table.
-
An empiracally derived table used for the quantization of the luminance and chrominance channels, the throwing away of information.
- Explain the origin of the phenomenon called blocking artifact.
-
JPEG divides the original picture into blocks of 8x8 pixels which are then ran through DCT. The higher the compression, the more of an approximation we’re looking at, the more pronounced are the edges of these blocks.
- How and why do we use predictive coding in JPEG standard?
-
Lossless predictive coding is in JPEG used on the DC value of each block.
- Describe the frame ordering in MPEG scheme.
-
The encoded ordering is different from the chronological ordering, so that bidirectionally predicted frames (B-frames) are stored after the frames they are compared against.
- What is a difference between I, P, and B frames?
-
I(ndepent) frame have all of the information; P(redicted) frames contain only the difference compared to the previous frames; B(idirectional) frames contains the difference compared to the previous and the chronologically next frame.
- How do we loose the information when using JPEG/JPEG2000?
-
-
By reducing the bandwidth of the Cb and Cr channels.
-
By using DCT/DWT and quantizing the coefficients.
-
- Why invent newer and newer image/video compression methods?
-
-
Resolution and computation capabilities goe up, but network bandwidth is limiting.
-
Storage is also costly.
-
Better quality for the same bandwidth.
-
- How does HEVC decide how deep is the quadtree inside a CTU?
-
-
Based on the signal characteristics of the region that is covered by the CTB [hevc-overview].
-
Luma and chroma CBs can be also split based on the prediction-type decision.
-
The minimum allowed Luma CB size is 8x8.
-
References
-
https://benchpartner.com/q/explain-about-lossy-predictive-coding
-
https://www.cmlab.csie.ntu.edu.tw/cml/dsp/training/coding/jpeg/jpeg/encoder.htm
-
HandyAndy Tech Tips, H.265 (HEVC) vs H.264 (AVC) Compression: Explained!, 2016
-
Christian Feldmann, Video Coding Basics - How is this so efficient?, 2022
-
[] Sullivan et al., Overview of the High Efficiency Video Coding (HEVC) Standard, 2012